
「AI」や「ビッグデータ」といった言葉がメディアに頻繁に登場するようになってからというもの、データの持つ重要性が未だかつてないほど高まっています。
ただ、どうしても数字を読むのは苦手だと感じる人も多いもの。
データをどのように扱うのかを知っている人と知らない人とで、大きな力の差がついてしまうということも考えられます。
データサイエンスの時代を生き抜くために必要とされる教養である「データリテラシー」を、どのようにして身につけていけばいいのでしょうか。
1.そもそも「データリテラシー」とは
「長年の経験と勘がモノを言う」
昔であれば、このような言葉をよく聞いたかもしれません。
ところが今や、AIを使って膨大なデータから特徴を抽出するということが可能になり、データを基に判断を下すというのが当たり前になりつつあります。
時代の流れも速くなり、いかに迅速に膨大なデータから有益な情報を取り出して、それを意思決定に反映させていくのかに多くの企業はしのぎを削っています。
データリテラシーに関するイメージとしてよくあるのが、Pythonのようなプログラミング言語や高度な統計解析の知識が必要になってくるということではないでしょうか。
確かに、データを集めて分析するためには、プログラミングや統計解析の知識も必要です。
しかし、データは集めて解析すれば、それで終わりではありません。
得られたデータを意思決定に活用するところまでできるというのが重要であり、プログラミングや統計解析を知っているというだけでは、データリテラシーがあるとは言えません。
例えば、一日平均で10個(月に300個)売れる商品があったとしましょう。
同じ商品であっても、毎日10個のペースで売れていく商品と、月末にまとまって300個売れる商品とでは、在庫管理の方法が異なってくるはずです。
どのタイミングで、どれだけ売れるのかまでちゃんと把握していれば、適切な仕入れや在庫管理を行うことができ、無駄を最小限に押さえることができます。
このように数字の意味を適切に解釈し、意思決定に反映させることが重要になってきます。
データリテラシーとは、単にプログラミングや統計学の知識を指すのではありません。
データを読み取って分析し、その結果を使いこなす能力であるという点に注意しておきましょう。
2.ちゃんと押さえておきたい統計用語の意味
統計データを扱ううえで、頻繁に出てくるのが平均値です。
平均値の求め方は、小学校で習います。
Excelでも簡単に計算することができ、平均値自体は誰でも簡単に求めることができます。
しかし、データリテラシーで大事になってくるのは、ちゃんとその意味を理解できているかどうかです。
驚くべきことに、大学生の4人に1人は平均の意味をちゃんと理解できていないという調査結果があります。*1
それでは、具体的にどのような点が誤解されやすいのでしょうか。
混乱が起きやすいのが、平均値、最頻値、中央値の違いです。
それぞれの違いを整理すると、以下のようになります。
平均値:全ての数値を足し合わせて、数値の個数で割ったもの
最頻値:数値の中で一番個数が多いもの
中央値:数値を大きい順、もしくは小さい順に並び変えた時に、真ん中にくるもの
分かりやすくするために、グラフで見ていきましょう。
よく目にするのが、以下に示す左右対称になったグラフです。

左右対称となっている分布のグラフ(筆者が作図)
このような形のグラフでは、平均値、最頻値、中央値が重なってしまうため、「平均値は、数値の個数として一番多くなる」だとか「平均値は真ん中にくる」といった思い込みが生じます。
それでは、次のような山が二つあるグラフではどうでしょうか。
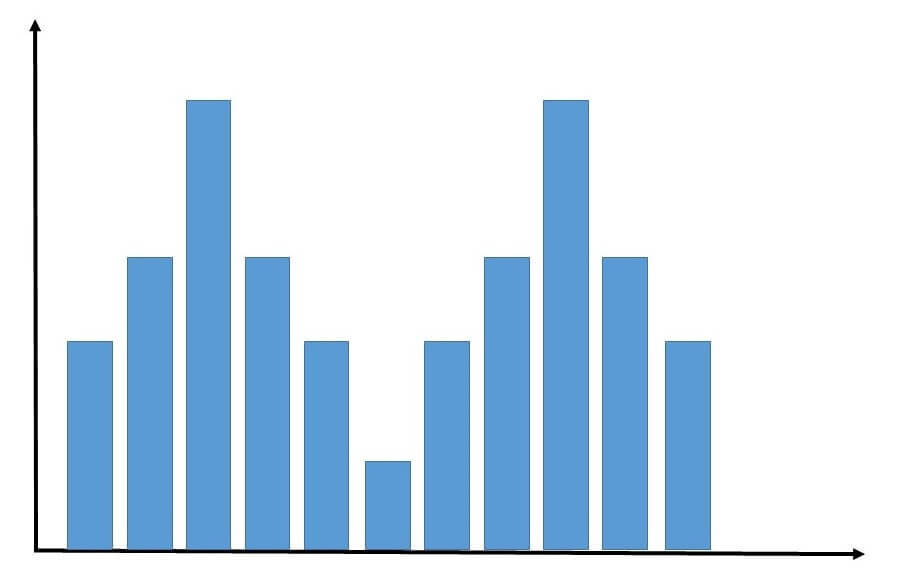
山が二つある分布のグラフ(筆者が作図)
数値の中に異なる二つのグループが混ざっているような場合には、このような分布になることがあります。
平均値と中央値は、真ん中の凹んだ部分になります。
最頻値は高くなっている部分であり、平均値は必ずしも数が多くなるわけではないというのが分かります。
さらに、左右非対称となった次のような形のグラフはどうでしょうか。
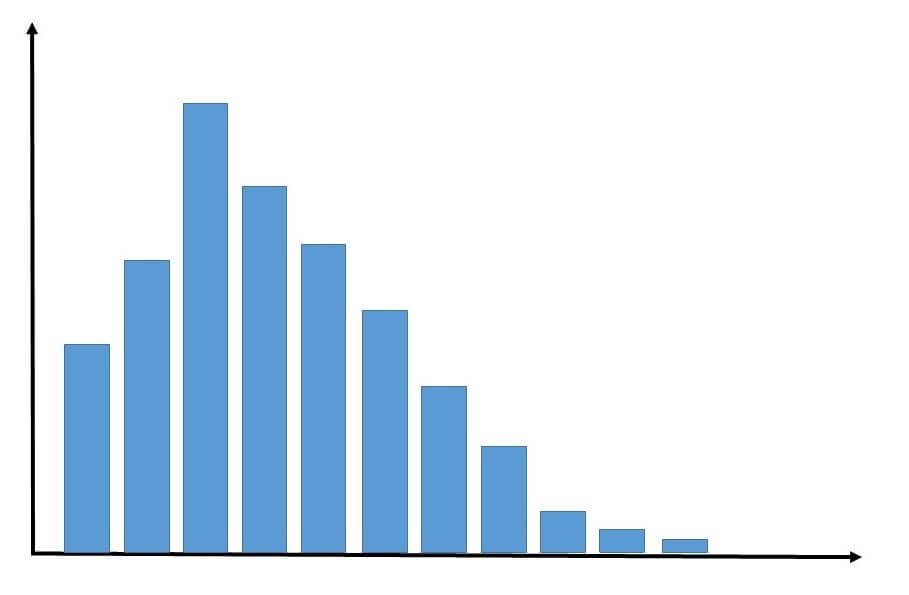
左右非対称な分布のグラフ(筆者が作図)
このように分布が左右非対称の形になると、平均値と中央値の値はズレてきます。
このような形の分布をしている実例が、所得の分布です。
実際のグラフで平均値と中央値を確認してみると、以下のようになります。
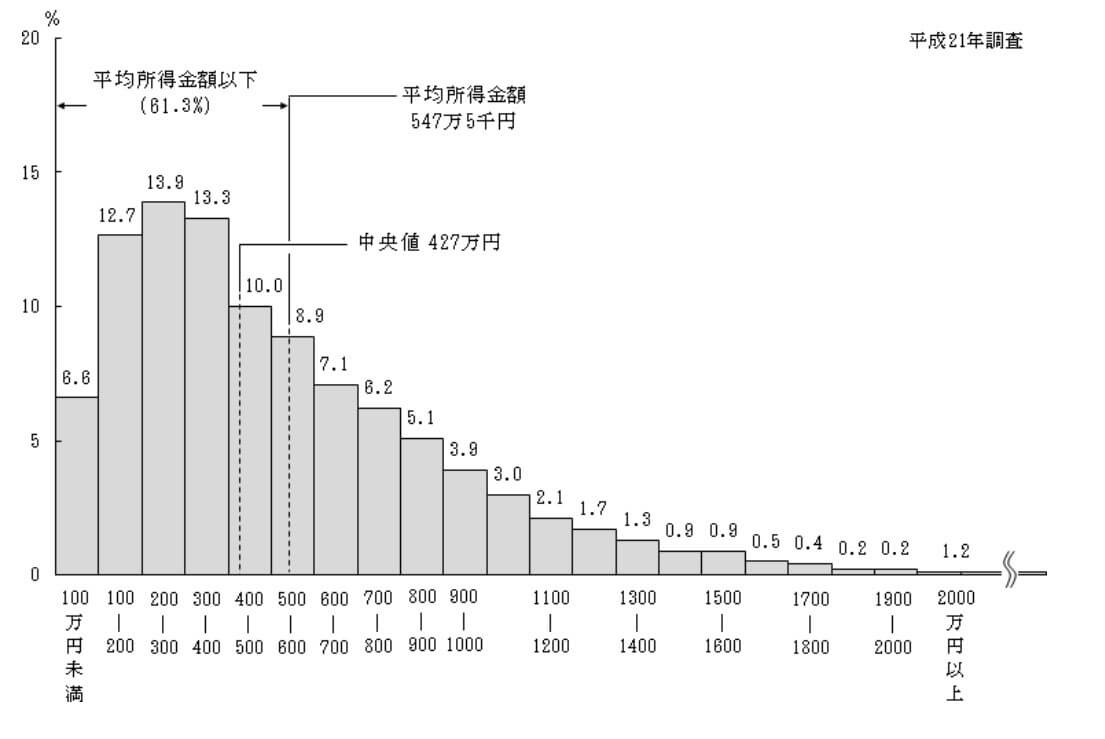
引用)厚生労働省「平成21年国民生活基礎調査の概況」
平均所得金額は、547万5千円だと言われても、「自分の周囲の人は、そんなに稼げているのか?」と疑問が出てくるのではないでしょうか。
平均値には、飛び抜けた値の影響を受けやすいというデメリットがあります。
そのため、ものすごく稼ぐ人がいると、その影響によって平均所得金額が押し上げられてしまうわけです。
このような場合には、飛び抜けた値の影響を受けずにする中央値である427万円で見た方が、実態をつかみやすいでしょう。
平均値、最頻値、中央値は、統計データを読みこなすうえで重要なものです。
この3つの値の違いや、グラフの分布の形にも注意しながら、データを読みこなせるようにしましょう。
3.無意識による思い込みには要注意
統計データに基づいて判断を下せば、方向性を間違ってしまうリスクを軽減できます。
データなど取らなくても感覚的にどうすればいいのか分かるという人もいるかもしれません。
しかし、感覚だけで判断を下そうとしてしまうと、無意識による思い込みによって判断を誤ってしまう可能性が出てきます。
例えば、飛行機事故と自動車事故を比べた場合、自動車事故の発生確率の方が高いにも関わらず、飛行機事故の方が怖いかのような印象を受けてしまいます。
これは、飛行機事故の方が大惨事になることが多く、報道で大々的に取り上げられることが多いのに対し、自動車事故はあまり取り上げられることがないためです。
人間の脳は、イメージしやすい出来事の発生確率を実際よりも高く見積もってしまいますが、そのような傾向は「利用可能性ヒューリスティック」と呼ばれています。*2
自動車事故の方が発生数は多いにも関わらず、飛行機事故の報道に触れる回数がまさってしまうことで、あたかも飛行機事故が多いかのような錯覚に陥ってしまうのです。
そのような錯覚に陥らないためにも、実際にデータを見て確認するということが大事になってきます。
一方で、統計データのことをある程度わかっていたとしても、無意識のうちに誤った判断を下してしまうということもあります。
例えば、「真面目で几帳面な人の血液型は?」と聞かれて、思わず「A型だ」と判断してしまった場合、思い込みによって判断していることになります。
血液型性格診断に科学的な根拠はないということは今となっては多くの人が知っています。
それにも関わらず、なんとなく特徴だけをとらえて判断してしまうのは、その方が脳にとっては手っ取り早くて楽に判断できるからです。
このように、対象とするものを象徴する特徴などをとらえて、それだけを使って判断や認識を行うことは「代表性ヒューリスティック」と呼ばれています。*2
複雑な統計解析よりも、ヒューリスティックによって答えを出した方が脳にとっては楽なので、油断すると無意識的にヒューリスティックで判断をしてしまうということになりかねません。
人間は無意識的に思い込みをしてしまうものなのだということは、知っておいた方がいいでしょう。
4.オープンデータにも目を向ける
データ分析しようとなると、十分な量のデータを集める必要があります。
データの量が多いほど精度は上がりますが、それだけのデータを確保するには、かなりの時間、労力、コストがかかります。
データサイエンスというと、かっこよく聞こえるかもしれませんが、その大部分は地道なデータ集めや、解析前の手間のかかる前処理です。
自分で集めようとする前に公開されているデータで使えるものがないか、まずは検討してみましょう。
公開されているデータの中で信頼性が高いのが、国や自治体が公開しているものです。
総務省統計局のホームページを見ると、日本の人口の他、消費者物価指数や完全失業率などのデータが表示されています。*3
家計や消費に関する統計調査の結果も公開されており、商品やサービスを企画するうえで役に立ちます。
この他にも、中央省庁ごとに白書や様々な調査結果などが公開されています。
これらの資料を組み合わせて利用することで、多角的に物事を捉えられるようになります。
データを集めたり、利用したりするうえで大事になってくるのが、目的や仮説をはっきりさせておくことです。
やみくもにデータを集めて分析していたのでは、大量のデータに振り回されてしまうということになりかねません。
データは、集めて分析したらそれで終わりではなく、それを商品やサービスの開発や意思決定に活用できてこそ価値があります。
AIやDXの時代において、データは一部の専門家だけが扱うものではありません。
データリテラシーを身につけ、思い込みに左右されない正確な意思決定ができるようにするということを意識されてみてはいかがでしょうか。